
























Un rapport de Scale AI révèle ce qui fonctionne et ce qui ne fonctionne pas avec la mise en œuvre de l’IA, et les meilleures pratiques pour les équipes ML afin de passer du simple test au déploiement dans le monde réel.
Pour les praticiens du ML (Machine learning), la qualité des données est l’un des facteurs les plus importants de leur réussite, et selon les personnes interrogées, c’est aussi le défi le plus difficile à surmonter.
Cette enquête, menée en ligne aux États-Unis par Scale AI auprès de 1 300 spécialistes de l’intelligence artificielle (dont ceux de Meta, Amazon, Spotify), confirme qu’il reste encore pas mal d’obstacles à surmonter pour tirer profit de cette technologie.
La preuve, plus d’un tiers (37 %) de tous les répondants ont déclaré ne pas disposer de la variété de données dont ils ont besoin pour améliorer les performances de leurs modèles. Le manque de transparence est également pénalisant.
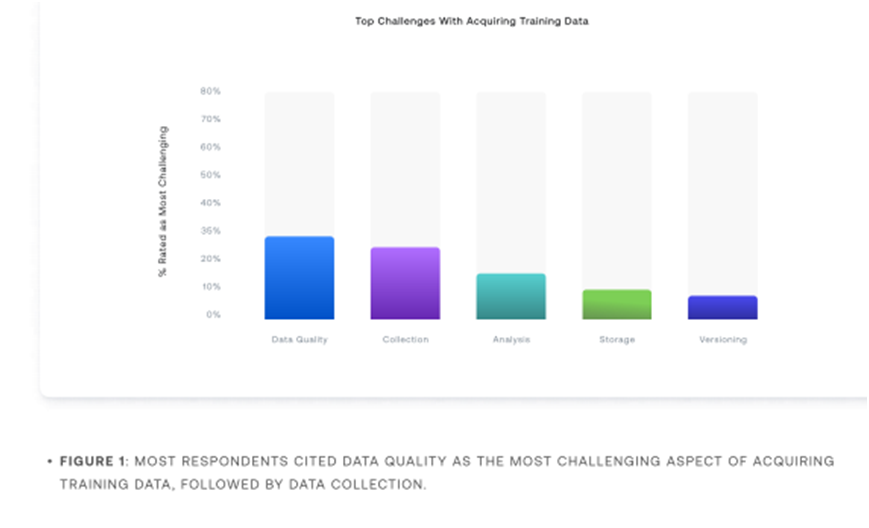
Non seulement ils ne disposent pas d’une variété de données, mais la qualité est également un problème. Seuls 9 % des répondants ont indiqué que leurs données de formation sont exemptes de bruit, de biais et de lacunes.
La majorité des répondants ont en effet des problèmes avec leurs données de formation. Les trois principaux problèmes sont le bruit des données (67 %), la partialité des données (47 %) et les lacunes du domaine (47 %).
La plupart des équipes, quel que soit le secteur d’activité ou le niveau d’avancement de l’IA, sont confrontées à des défis similaires en matière de qualité et de variété des données.
Les données de Scale AI suggèrent que travailler en étroite collaboration avec des partenaires d’annotation peut aider les équipes ML à surmonter les défis liés à la curation des données et à la qualité des annotations, accélérant ainsi le déploiement des modèles.
« Nos analyses révèlent une tendance clé de la préparation à l’IA : il existe une relation linéaire entre la rapidité avec laquelle les équipes peuvent déployer de nouveaux modèles, la fréquence à laquelle elles recyclent les modèles existants et le temps nécessaire pour obtenir des données annotées. Les équipes qui déploient rapidement de nouveaux modèles (notamment en moins d’un mois) ont tendance à obtenir des données annotées plus rapidement (en moins d’un mois)que celles qui prennent plus de temps à déployer », lit-on dans ce rapport.
Mais la vitesse d’obtention des données annotées n’est pas le seul facteur important. Les équipes ML doivent s’assurer que les bonnes données sont sélectionnées pour être annotées et que les annotations elles-mêmes sont de haute qualité.
L’alignement de ces trois facteurs - sélection des bonnes données, annotation de haute qualité et annotation rapide - est essentiel. Sans cet alignement, l’adoption de l’IA se fera à pas comptés.













