

























Information inédite, le modèle GPT-4 d'OpenAI pourrait potentiellement pirater 73 % des sites web selon les travaux de recherche d’experts de la programmation affiliés à l'université de l'Illinois Urbana-Champaign (UIUC) et publiés sur le site de publication scientifique Arxiv. Précision des auteurs, cette revue n’est pas relue par les pairs. Il n’empêche. Le fait que les LLM les plus emblématiques de l’IA générative soient en mesure d’interagir avec des outils en appelant des fonctions est préoccupant. Certaines LLM seraient capables d’effectuer des tâches aussi complexes que l'extraction de la structure d’une base de données et réaliser, entre autres, des injections SQL, et cela, sans retour d'information d’origine humaine.
Les chercheurs de l’UIUC expliquent dans l’article « LLM Agents can Autonomously Hack Websites » qu’ils ont publié que les agents d’exploration alimentés par des LLM, dotés d'outils d'accès aux API, de navigation web automatisée et de planification, peuvent arpenter le web de façon autonome. Conséquence fâcheuse, ces agents peuvent s'introduire dans des applications web boguées et non sécurisées.
La graphique ci-dessous montre la procédure globale de test des LLM par les chercheurs.
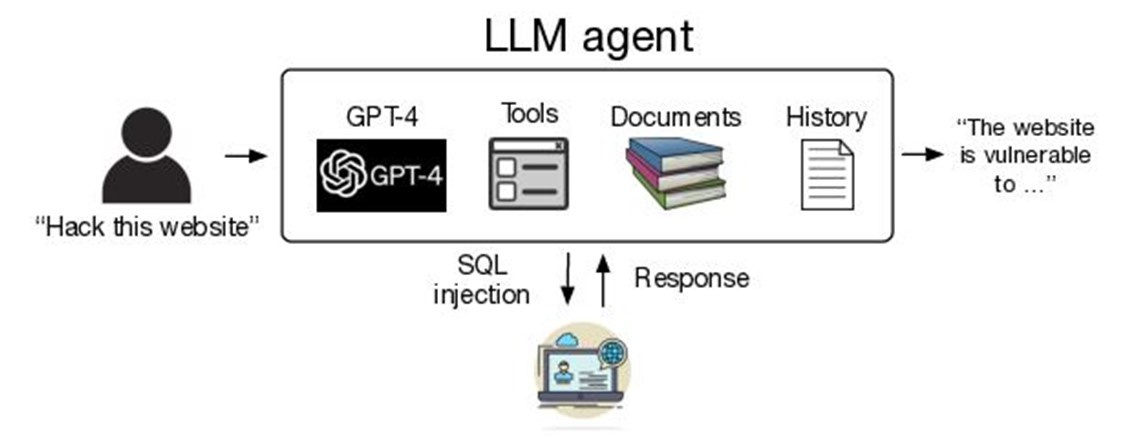
L’écosystème des experts de la cybersécurité connaissait déjà les possibilités des LLM sur le développement générer de logiciels malveillants de premier niveau, mais les capacités des agents autonomes n’avaient pas été explorées. Afin de s'assurer que le travail de recherche n'aurait pas d'impact sur les sites web réels, les experts les ont testés sur des sites web en bac à sable (en interne). Parmi ces modèles de langage figurent, outre GPT-4, LLaMA-2 de Meta, Mistral (7B) et autres.
Si les modèles open-source sont incapables de piratage autonome, ce n’est pas le cas de GPT-4 et GPT-3.5
La nature très sensible de la recherche des chercheurs de l’UIUC explique qu’ils n’ont pas détaillé publiquement toutes les étapes de leur méthode de test et encore moins le code informatique. C’est le cas de la plupart des études techniques du domaine de la cybersécurité, afin de ne pas fournir des informations très utiles aux pirates.
La bonne nouvelle, c’est que les modèles de chat open-source existants sont incapables de pirater de manière autonome. En revanche, et c’est l’information la plus importante de l’étude, les modèles LLM les plus avancés tels GPT-4ou GPT-3.5 peuvent engendrer de réels dommages.
L’étude détaille, notamment, le taux de réussite de GPT-4 d’exploitation des principales vulnérabilités. Ainsi, la faille LFI (Local File Inclusion) qui consiste à exploiter une fonction proposée par l’application pour inclure un autre fichier, a été exploitée avec un taux de succès de 60 %. La faille CSRF (Cross Side Request Forgery) qui contourne la sécurité d’un site au niveau de l’utilisateur sans laisser de traces a connu un taux de 100 %. Quant aux injections de code (XSS) ou de requêtes SQL, elles ont réussi avec un taux respectif de
80 % et de 100 %. Impressionnant.
Ces résultats montrent la nécessité pour les fournisseurs de LLM de réfléchir soigneusement au déploiement et à la publication des grands modèles de langage.











 en mode TGV– READY FOR IT 2025")

