


Les entreprises produisent et stockent de plus en plus de données, et les conservent sur des périodes qui s’allongent ! Que faire de toutes les données accumulées ?
Confrontées à l’explosion des données produites par les utilisateurs, et/ou accessibles, à l’évolution des exigences règlementaires, à l’allongement des cycles juridiques, ainsi qu’au manque de solutions pour comprendre et catégoriser les données de manière prédictive, les organisations conservent toujours plus de données, principalement non structurées.
C’est là que les DSI, les CDP (Chief Data Officer) et les administrateurs du stockage se posent la question : que faire de toutes ces données accumulées ? Tant que l’on était sur des données structurées, c’est à dire organisées dès leur conception ou leur intégration, la réponse était relativement simple : sur un temps moyen, répondant aux obligations juridiques de conservation de l’information, les données étaient conservées dans le SI, et en théorie sorties pour être archivées à l’échéance de ses délais.
Confrontés à une quantité croissante des données, dont une majorité est généralement mal maîtrisée, à la volonté parfois maladive des directions générales et financières, et des responsables compliance et gouvernance de tout conserver et pour toujours, et profitant du prix du stockage à la donnée qui ne cesse de baisser, la DSI tendait à ne pas appliquer de règles de conservation, mais à dynamiser le stockage pour tenter d’identifier les données stratégiques, celles qui doivent être accessibles le plus rapidement.
Stocker plus à moindre coût
Aujourd’hui, l’explosion des volumes et des règles a complexifié cette approche. Lancer une solution non gérée de stockage de données qui repose sur la croissance incontrôlée des volumes n’est plus rentable. La courbe du cycle de vie des données s’est désormais divisée en deux, avec deux facteurs différentiants : le coût du stockage et le coût de la recherche. Hors le second explose tandis que le premier se réduit.
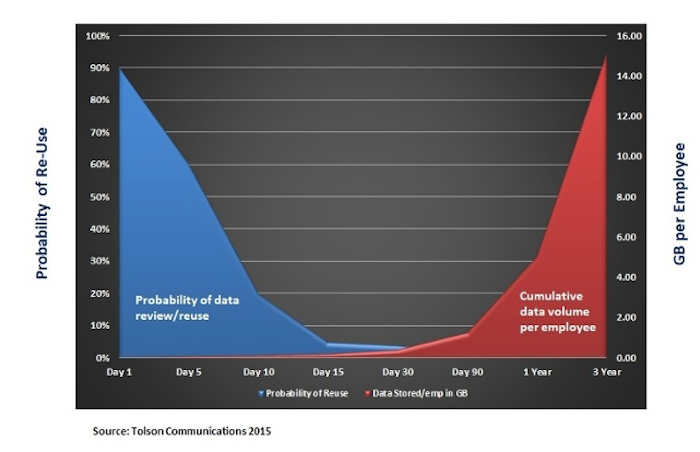
La ‘durée de vie utile’ d’une donnée est très courte, en moyenne 15 jours avant que la probabilité de réutilisation de la donnée passe sous la barre de 1 %. Par contre, cette information qui vieillit vite s’accumule, d’une part en se démultipliant – en moyenne une photo serait dupliquée à minima 6 fois (un original + une copie v2 + une copie v3 + une publication sur un réseau + une expédition par mail + etc.) - et en s’accumulant. La probabilité que la version 1 du document soit ouverte est quasiment à 0, sans l’être totalement cependant. Même chose pour les v2, v3, etc., mais la probabilité se rapproche plus encore du 0. En revanche, la v1 est rarement supprimée, et elle subsiste indéfiniment en tant que donnée inactive ! Et les autres suivent, le schéma est infernal pour le stockage...
La segmentation par la valeur de la donnée
Le DSI et le responsable du stockage se retrouvent confrontés à une équation délicate : appliquer des règles qui permettent de segmenter les données. Ces règles existent, elles appliquent une valeur à la donnée : données soumises à une autorisation légale ; données soumises à des exigences réglementaires en matière de conservation ; données disposant d’une valeur commerciale directe ; et données d'une valeur inconnue.
Une étude GCOC révèle l’importance de ces segments de base :
- 1% des données sont généralement soumises à une autorisation légale ;
- 5% à des exigences réglementaires en matière de conservation ;
- 25% ont une valeur commerciale directe ;
- 69% des données sont d'une valeur inconnue.
Il serait simple de définir la valeur inconnue comme le critère de sélection de la donnée. Le problème, avec la paranoïa réglementaire des défenseurs de la conservation des données et les pratiques du Big Data et du machine learning qui reposent sur des volumes de données toujours plus importants, est qu'il est évident que la valeur inconnue d’un document ne peut se traduire par sa suppression.
Une gestion intelligente des données rend nécessaire aujourd’hui de les classifier. Donc de définir des valeurs pour leur stockage dans des strates d’architecture qui les rendent plus ou moins rapidement accessibles. Mais, la majorité des entreprises n’a ni le temps ni les ressources pour catégoriser les données, la majorité reste donc non classifiées, et les entreprises se rabattent une nouvelle fois sur leur conservation.
Vers un archivage intelligent
Conformité réglementaire, e-discovery, historique d'entreprise et analyse des données… Le maintien de la conformité à la réglementation et la découverte numérique impliquent la nécessité de consolider l'information afin qu'elle puisse être recherchée et produite sur demande et dans un délai acceptable. D'un autre côté, les données conservées pour des raisons d'historique d'entreprise et d'analyse de données ne nécessitent généralement pas de recherche et de production rapides, mais doivent également être consolidées pour faciliter la recherche et la production.
La solution est certainement dans le stockage et l’archivage intelligents et hybrides des données, sur le cloud privé de l’entreprise pour les données stratégiques et à forte valeur, et dans le cloud public pour un archivage ‘low cost’ des données inactives. Si l’on se réfère à l’expérience des grands acteurs du cloud, 31 % des données stockées dans le nuage seraient chaudes, c’est à dire active et semi-actives, et 69 % des données froides considérées comme très inactives qui seraient stockées et gérées au niveau Archive low cost.
En conclusion
En réalité, l’optimisation du stockage, et pas seulement du coût du stockage, repose sur trois niveaux qui prennent en compte le cycle de vie de la donnée :
- la donnée active ‘fraiche’ - la fraicheur est une période de 15 jours après sa création - sur le poste de travail ou sur l’infrastructure (on premise ou cloud privé) de l’entreprise ;
- la donnée active ou semi-active ‘chaude’ stockée sur le SI ou dans le cloud ;
- la donnée inactive ‘froide’ archivée, principalement aujourd’hui dans le cloud low cost.
Image d’entête 680427352 @ iStock invincible_bulldog





















