


Le Gartner a réuni et analysé dans un Magic Quadrant 16 fournisseurs de solutions Data Science, avec un focus particulier sur l’apprentissage automatique. Une analyse bien venue alors que beaucoup d’organisations se sont lancées dans les analytiques et annoncent s'intéresser à l’IA (Intelligence Artificielle) appliquée à la donnée.
Les organisations qui se lancent dans la construction de leurs propres modèles de Data Science (analytiques des données) et de Machine Learning (apprentissage automatique) en interne ont besoin de s’appuyer sur des plateformes logicielles, qu’elles développent des types d’analytiques spécifiques ou recherchent des solutions verticalisées.
Le Gartner considère que, bien que Data Science et Machine Learning soient légèrement différents, ils sont généralement considérés ensemble et souvent considérés comme synonymes. Le terme "machine learning" est le terme le plus utilisé dans les supports marketing des fournisseurs. Il apparaît fréquemment dans les recherches effectuées sur ce marché. Les analystes du Gartner considèrent que le nom du Magic Quadrant reflète l'élan de l'apprentissage automatique et son importante contribution à la discipline plus vaste de la Data Science.
Ainsi, une plate-forme de Data Science assiste les experts de la donnée dans l’exécution de tâches sur l’ensemble du pipeline de données et d’analyses. Celles-ci incluent des tâches liées à l'accès et à l'ingestion de données, à la préparation des données, à l'exploration et à la visualisation interactives, à l'ingénierie des fonctionnalités, à la modélisation avancée, aux tests, à la formation, au déploiement et à l'ingénierie des performances.
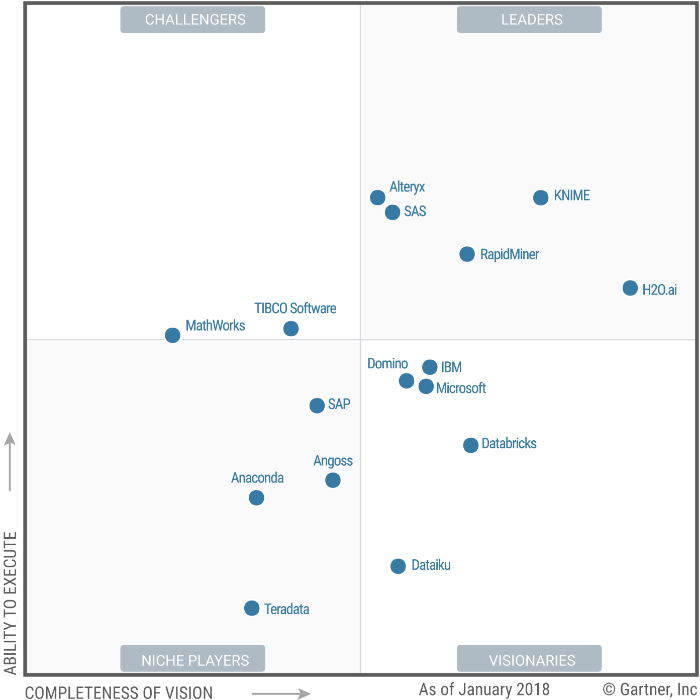
Ce Magic Quadrant Data Science et Machine Learning s’adresse :
Aux équipes data scientists métiers, généralement parrainées par les dirigeants de leur secteur d'activité et chargées de traiter les initiatives menées par ce secteur dans des domaines tels que le marketing, la gestion des risques et la gestion de la relation client.
Aux équipes data scientists d'entreprise, qui bénéficient d'un large soutien de la part des dirigeants et peuvent adopter une perspective inter-fonctionnelle à partir d'une position de visibilité à l'échelle de l'entreprise. En plus de soutenir la construction de modèles, ils sont souvent chargés de définir et de soutenir un processus de bout en bout pour la création et le déploiement de modèles de science des données et d'apprentissage automatique. Ils travaillent souvent en partenariat avec des équipes métier au sein d'organisations multiniveaux.
Aux scientifiques "non-conformistes", généralement des scientifiques uniques dans diverses unités du secteur d'activité, qui ont tendance à travailler indépendamment sur des solutions ‘ponctuelles’ et privilégient généralement fortement les outils open source, tels que Python, R et Apache Spark. Et qui collaborent rarement avec d'autres data scientists de leur organisation.
Aux titulaires de rôles supplémentaires, tels que data scientist citoyen, ingénieur informatique et développeur d'applications. Ils doivent comprendre la nature du marché de la science des données et de l'apprentissage automatique, et en quoi il diffère, mais complète, le marché de l'analyse et de la business intelligence (BI).
Source : Le Gartner Magic Quadrant Data Science et Machine Learning est accessible ici.
Image d’entête 979188930 @ iStock Photo z_wei





















