




























Des milliers de milliards de tokens -à savoir un mot ou partie de mot- sont utilisés pour entraîner le LLM de ChatGPT 4. L’IA générative de Meta, LLama 3 aurait nécessité 15.000 milliards de Tokens. Les ordres de grandeur du volume de données entrantes sont tout aussi colossaux pour les autres LLM telles Claude d’Antropic, Gemini de Google et autres IAGen.
Ces modèles de langage permettent de comprendre les requêtes et formuler des réponses pertinentes. L’université américaine Cornell a publié une étude intéressante sur les contraintes potentielles de la mise à l'échelle des LLM, posées par la disponibilité de données textuelles publiques générées par l'homme. L’objet de cette recherche académique est de prévoir la demande croissante de données d'entraînement des LLM sur la base des tendances actuelles puis d’estimer le stock total de données textuelles humaines publiques.
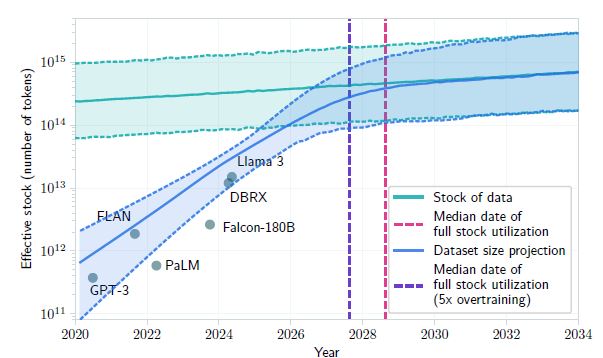
Principal résultat, si les tendances actuelles du développement des LLM se poursuivent, les modèles seront entraînés sur des ensembles de données d’une taille à peu près égale à la totalité du stock disponible de données publiques, entre 2026 et 2032. Voire plus tôt, si les modèles de LLM sont surentraînés comme ils le sont à ce jour. Cependant et pour pondérer ce résultat, l’étude de Cornell cite Dario Amodei, PDG d'Anthropic qui estime à 10 % de risque que l'évolution des systèmes d'IA stagne en raison d'un manque de données. A savoir une faible probabilité.
Le graphique ci-dessous montre l’utilisation des données publiques disponibles par les LLM sur une échelle de temps. La stagnation est attendue avant 2028 pour la date médiane d'utilisation du stock complet (pointillé rouge) et plus tard en cas du surentrainement des modèles (pointillé violet).
D’autres sources de données devraient prendre le relais et permettre aux LLM de continuer à se développer
Face à la pénurie possible de données textuelles humaines publiques, les chercheurs de Cornell explorent les solutions pour contourner ce goulet d’étranglement. Trois pistes sont envisagées.D’une part, la génération de données synthétiques et non-publiques créées par des algorithmes qui reproduisent les propriétés statistiques des données réelles, sans révéler d’informations sur des personnes réelles pour préserver la confidentialité. Etant donné l’extrême sensibilité du sujet et notamment la présence de l'IA ACT européen qui catégorise la nature sensible des données utilisées par les IA, il est à prévoir que cette solution sera très problématique à mettre en œuvre sur le plan législatif.
D’autre part, l’étude envisage l'apprentissage à partir de l'utilisation de données non publiques. Là aussi, la voie parait impossible à suivre car il s’agit, notamment, des données personnelles des réseaux sociaux et autres domaines privés. Il s’agit donc d’une piste très théorique.
La troisième solution mentionnée par l’étude est plus crédible et réaliste, celle de l’optimisation des modèles de machine learning actuels qui permettrait des gains de performance des LLM.



















