




























Le Big Data ou exploitation des données massives doit aujourd’hui répondre à l’appétit insatiable de l’IA générative, du secteur financier, de l’analyse prédictive et à moindre titre, des exigences réglementaires. Les contraintes restent les mêmes qu’avant l’émergence de ces nouvelles demandes, il faut toujours stocker, traiter et analyser un volume pléthorique de données structurées, trier le bon grain de l’ivraie, tout en les sécurisant.
A cela s’ajoute la gestion complexe des types de données émergentes issues des réseaux sociaux, des systèmes IoT en temps réel, des données géolocalisées, etc.
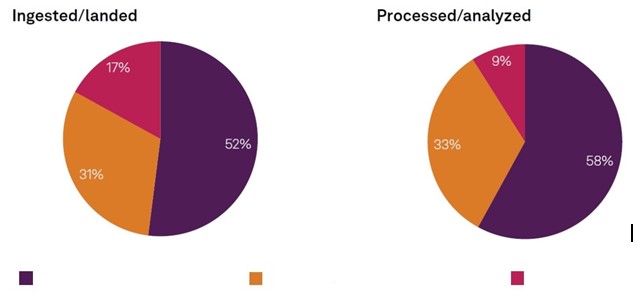
L’étude de BMC « Putting the “Ops” in DataOps: Success factors for operationalizing data» met le focus sur la très faible prise en compte à ce jour des données émergentes. A ce jour, elles ne représentent que 17 % des données ingérées ou reçues. Sans surprises, uniquement 9 % de ce type de données sont traitées ou analysées, comme l’indique le graphique ci-dessous.
Le graphique de gauche indique la proportion de données collectées. Celui de droite, celles qui sont traitées et analysés.
 Légende couleurs : de gauche à droite > données héritées / données traditionnelles / données non-structurées (temps réel, géolocalisées, images, vidéos, etc.)
Légende couleurs : de gauche à droite > données héritées / données traditionnelles / données non-structurées (temps réel, géolocalisées, images, vidéos, etc.)
Source: S&P Global Market Intelligence 451 Research and BMC Global Data Management study, 2024
Les données héritées (legacy) représentent 52% des informations collectées, auxquelles s’ajoutent 31% de données classiques, structurées. Les types plus anciens de données réellement traitées et analysées constituent la grande majorité des informations réellement exploitées avec une proportion de 91% du total.
Les contraintes du manque de profils spécialisés et de l’évolution des outils spécialisés Une stratégie efficace DataOps (contraction des termes DataScience et DevOps) s’appuie sur la maturité de la gestion des données. Parmi les répondants estimant qu’ils disposent d’une maturité exceptionnelle en matière de gestion des données, 27 % déclarent utiliser des méthodes DataOps dans l'ensemble de leur organisation contre 19 % pour les organisations ayant un niveau de maturité moyen.
L’IA générative, grande consommatrice exige une gestion efficiente des données, exploite des modèles développés en interne ainsi que des technologies d'IA acquises sur le marché. Dans l’étude de BMC, 61 % des répondants disent gérer les informations de leur entreprise pour soutenir spécifiquement les projets de l’IAGen.
L’analyse prédictive pour des applications concrètes, maintenance et autres, est aussi en quête de grands volumes de données. Dans les deux ans à venir, 62 % des répondants prévoient un taux élevé de consommation de données pour l'analyse prédictive.
Les défis à relever sont, globalement, ceux de la filière IT. En tête, le manque de compétences (48 %), les erreurs humaines (43 %), les limites posées par l'évolutivité (40 %). Les fournisseurs de solutions tels BMC mettent en avant le manque d'automatisation des technologies (43 %) mais il ne s’agit pas de baguettes magiques. Sans une vision correcte des problèmes liés aux données massives, les résultats attendus ne seront
pas au rendez-vous.














