sur les projets.
Un rapport de SQream portant sur 300 experts de la gestion des données dans les grandes entreprises américaines confirme le résultat d’autres études sur le sujet et enfonce le clou en précisant que la plupart des équipes dédiées ont connu des échecs en 2023. En cause, une mauvaise qualité des données, les coûts prohibitifs des ressources qui poussent les organisations à arbitrer sur la complexité des requêtes, la taille des projets et le volume des données. Selon SQream, près de la moitié des personnes interrogées a admis qu'elles font des compromis sur la complexité des requêtes (48 %) et sur le volume
des projets (46 %). Cela concerne en particulier les dépenses cloud.
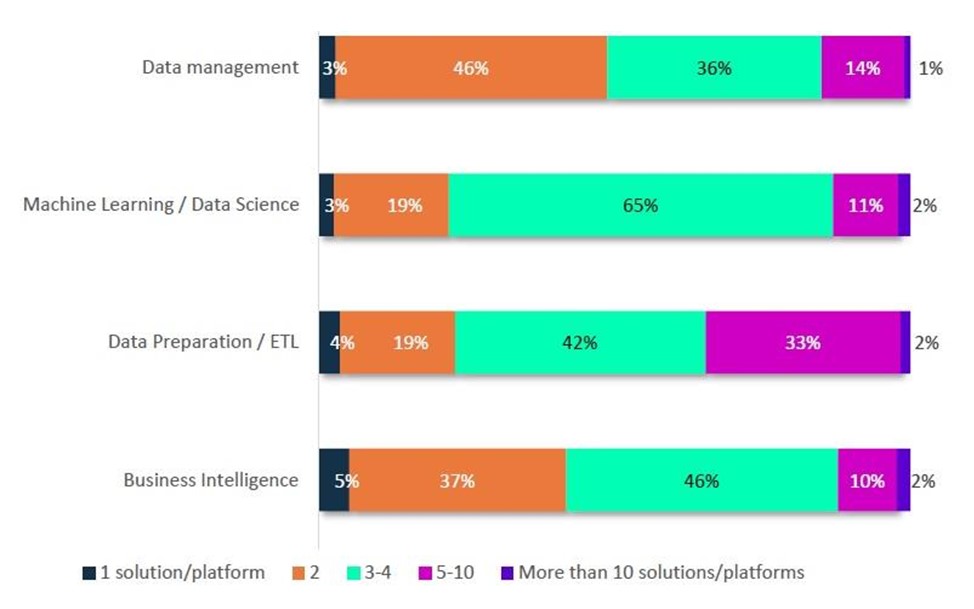
Manifestement, les responsables sont noyés dans les offres des fournisseurs. Pour ne citer que la préparation des données, un tiers des entreprises interrogées (33 %) utilisent 5 à 10 solutions ou plateformes, un chiffre pléthorique qui complique singulièrement les opérations. La graphique ci-dessous donne un aperçu explicite du nombre d'outils, de plateformes ou de solutions liés aux données utilisés pour chaque tâche.
Des factures douloureuses liées à l’analyse des données pour 41 % des entreprises
Au-delà des promesses annoncées par les fournisseurs de solutions, les coûts sont un défi pour les organisations. Ainsi, le principal facteur d'échec des projets de Machine Learning (ML) en 2023 est l'insuffisance du budget (29 %). Sans surprises, 41 % des entreprises considèrent les coûts élevés de l'expérimentation en ML comme le principal défi associé à l'analyse des données.Ces problèmes de coûts ne doivent pas occulter, les autres principaux facteurs d'échec que sont la mauvaise préparation des données (19 %) et le mauvais nettoyage des données (19 %). Ce n’est pas anecdotique. Pour un meilleur retour sur investissement des projets de ML, le choix d’une plateforme permettant plus d'itérations à coût raisonnable
semble pertinent.
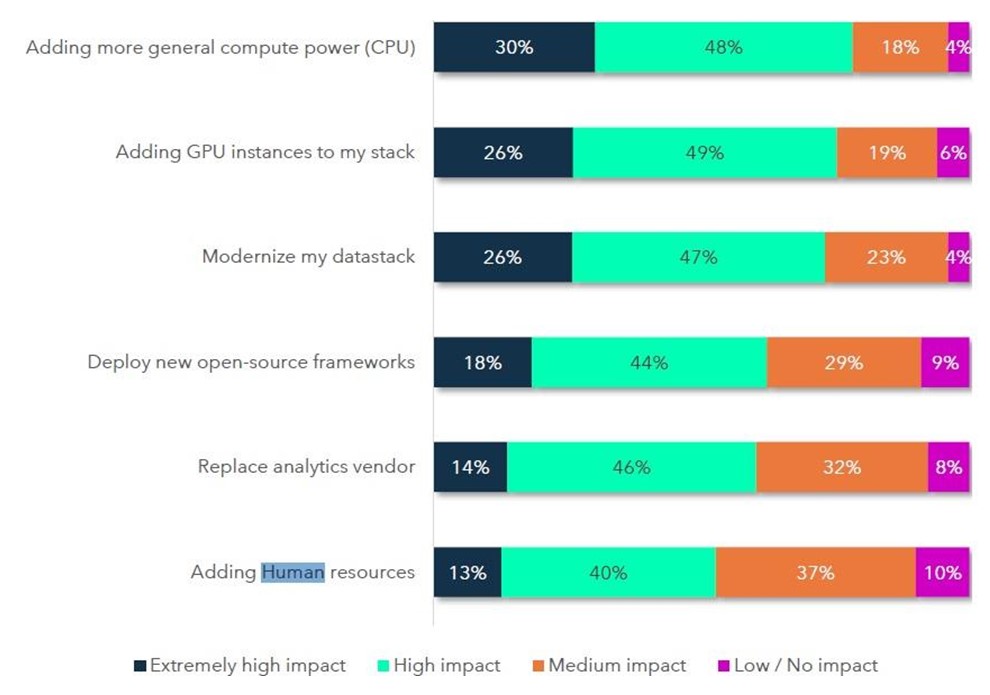
L’ajout constant de CPU n’est pas une solution pérenne
Ajouter de la puissance de calcul via l’ajout de CPU ne permet pas d’améliorer les performances au-delà d’un certain niveau de taille et de complexité. Traitant les données destinées au ML sous forme de vecteurs, les GPU (processeurs graphiques) sont particulièrement adaptés, une aptitude remarquable qui a porté le fabricant Nvidia de puces graphiques vers les sommets de la capitalisation boursière.Comme indiqué dans le graphique ci-dessous, l'ajout d'instances GPU est cité par 75 % des répondants comme un facteur essentiel de réussite. Parmi les autres causes majeures qui impactent les objectifs d’analyse des données pour l’IA et le machine learning, figurent la modernisation de la pile technologique (26 % des réponses), le déploiement d’un framework open-source (18 %), le changement de fournisseur (14 %) et enfin, pour 13 % du panel, le recrutement ou la montée en compétences de spécialistes de la donnée. Un chiffre faible qui semble sous-estimer l’importance des compétences face aux outils censés être la solution aux enjeux.