


Graphcore, société britannique qui conçoit et fabrique des systèmes informatiques spécialement conçus pour l’intelligence artificielle, autour de son processeur Intelligence Processing Unit (IPU), vient d’annoncer des benchmarks surpassant nettement certains GPU, notamment ceux de nVidia. Créée en 2016 par Nigel Toon et Simon Knowles, respectivement CEO et entrepreneur dans les semiconducteurs, et CTO et EVP ingénierie, Graphcore a été bâtie pour développer des microarchitectures spécialisées dans le traitement de charges de travail liées à l’IA : apprentissage et inférence.
Elle commercialise plusieurs produits pour équiper les centres de données, sous forme d’appliances et de Pod (les IPU-Pod), des sortes de mini-ordinateurs pour construire des supercalculateurs de traitement de l’IA. Enfin, côté logiciels, l’entreprise édite le SDK Poplar, un outil conçu pour fonctionner avec l’IPU pour simplifier le développement et le déploiement d’applications. Poplar SDK s’appuie sur les bibliothèques PopLibs, qui sont open source et disponibles sur GitHub avec une documentation en libre-service, des tutoriels et des guides.
Une microarchitecture novatrice pour l’IA
L’architecture de l’IPU et son paradigme de calcul ont été conçus conjointement à partir de zéro pour s’attaquer spécifiquement aux charges de travail de l’intelligence artificielle. Ils comportent certains choix de conception qui les différencient radicalement des architectures les plus courantes comme les CPU et les GPU. Avec ses 59,4 milliards de transistors, et construit selon le procédé TSMC 7nm, le Colossus MK2 GC200 IPU est le processeur de dernière génération de Graphcore.
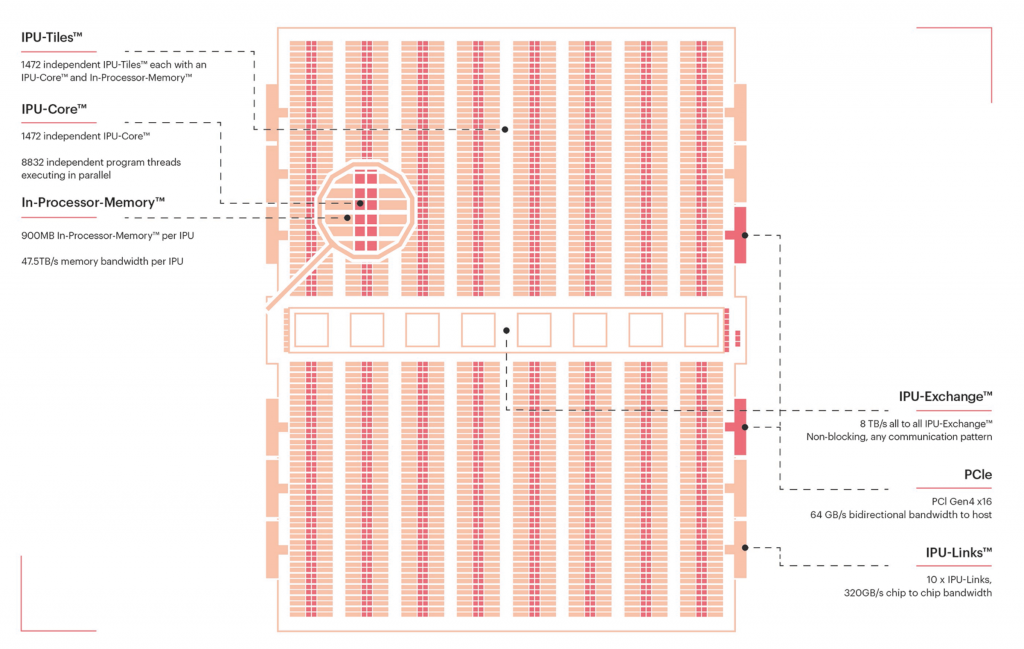
La microarchitecture du MK2 IPU se compose de Tiles comportant chacun 1472 cœurs disposant chacun de sa mémoire dédiée, soit au total une mémoire distribuée de 900 Mo par processeur, et une bande passante mémoire globale de 47,5 To/s. Chaque Tile exécute 8 832 threads par cycle d’horloge. Les capacités de communications internes, de Tile à Tile, du MK2 reposent sur l’IPU Exchange, un ensemble de contrôleurs non bloquants qui permettent des transferts allant jusqu’à 8 To/s. Les communications externes reposent sur de classiques bus PCI x16, soit 64 Go/s en bidirectionnel. Les liens entre les IPU sont assurés par dix IPU-Links propriétaires proposant une bande passante de 320 Go/s de puce à puce.
5,3 fois plus rapide que le dernier DGX-A100
Architecturé de manière à exécuter efficacement les opérations à grain fin sur un nombre relativement important de threads parallèles, l’IPU, contrairement à d’autres architectures massivement parallèles (par exemple, le GPU), est mieux adapté aux calculs à grain fin et irréguliers qui présentent des accès irréguliers aux données, selon ses concepteurs. Il offre un véritable parallélisme MIMD (instructions multiples, données multiples) et dispose d’une mémoire locale distribuée comme seule forme de mémoire sur l’appareil.
Pour toute une série de modèles courants, les technologies Graphcore ont largement surclassé le système A100 (basé sur DGX) de nVidia, tant au niveau de l’apprentissage que de l’Inférence. Avec un temps d’apprentissage 5,3 fois plus rapide que le dernier DGX-A100 de Nvidia (soit > 2,6 x plus rapide qu’une configuration dual-DGX), le résultat BERT-Large souligne le potentiel de la solution évolutive IPU-POD de Graphcore pour les centres de données. Il repose sur la pile logicielle Poplar pour gérer des charges de travail complexes qui tirent parti de plusieurs processeurs travaillant en parallèle.
Résultats des benchmarks :
- Apprentissage
EfficientNet-B4 : débit 18x plus élevé
ResNeXt 101 : débit 3.7x plus élevé
BERT-Large : apprentissage 5.3x plus rapide sur un IPU-POD64 par rapport à une station DGX A100 (>2.6X plus rapide que le dual-DGX)
- Inférence
LSTM : débit >600x avec une latence plus faible
EfficientNet-B0 : débit 60x/latence >16x plus faible
ResNeXt 101 : débit 40x/latence 10x plus faible
BERT-Large : débit 3.4x plus élevé avec une latence plus faible






















