






 par ingénierie sociale")




Fivetran, le spécialiste de l’intégration de données automatisée, annonce la publication de la deuxième édition de son benchmark annuel, qui compare les performances et les coûts des principales plateformes de données du marché. L’éditeur constate dans cette ultime itération de son comparatif que le marché est de plus en plus homogène. « Au cours des deux dernières années, les principaux datawarehouses dans le cloud se sont rapprochés en termes de performances », remarque-t-il.
RedShift et BigQuery ont, tous deux, fait évoluer leur expérience utilisateur pour la rapprocher de celle de Snowflake. Le marché converge aujourd’hui autour de deux principes : la séparation des traitements et du stockage, et une tarification au forfait, avec des « pics » pour tenir compte de flux intermittents.
En fait, tous les datawarehouses testés offrent d’excellents niveaux de coût et de performance. « Ce résultat n’est pas étonnant, car les techniques de base pour construire un data warehouse en cylindres performant sont bien connues, explique le rapport. Toutes les solutions utilisent donc les mêmes recettes standards pour optimiser leurs performances : stockage en cylindres, planification des requêtes basée sur les coûts, exécution par pipeline et compilation juste à temps ».
Les principales différences entre les plateformes testées se révèlent au niveau qualitatif, en raison de choix de conception différents. Certaines mettent en avant les capacités de configuration et de réglage, d’autres la simplicité d’utilisation. La meilleure stratégie pour les entreprises est donc de tester plusieurs solutions, et de choisir celle qui offre le meilleur équilibre correspondant à ses besoins.
À chaque solution ses spécificités
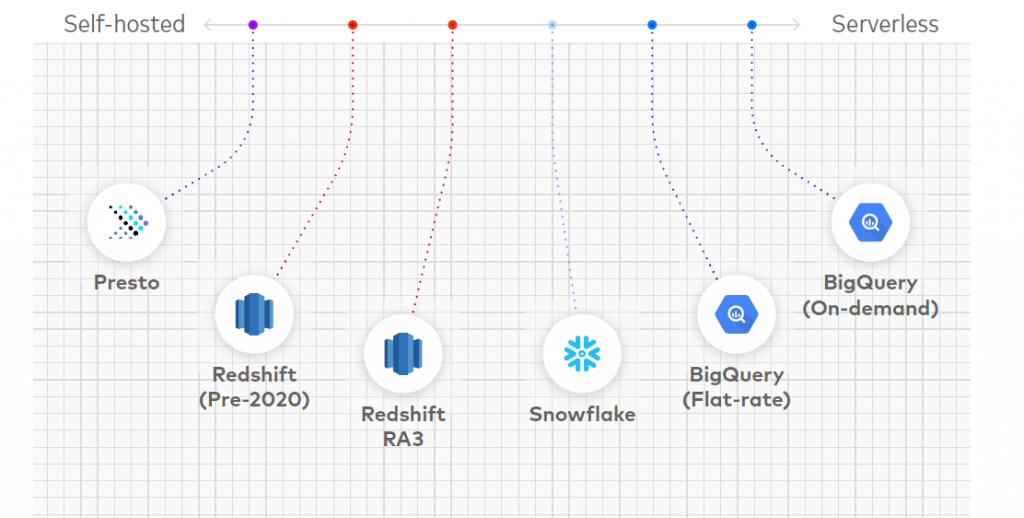
À gauche du côté « Self hosted » du spectre, on trouve Presto, qui laisse à l’utilisateur l’entière responsabilité de la fourniture des serveurs et de l’ensemble de la configuration du cluster. Presto est une solution open source, à la différence des autres systèmes présents dans le benchmark.
Pre RA3 RedShift intègre plus de fonctionnalités de gestion que Presto, mais exige toujours de l’utilisateur de configurer les clusters de traitement individuels avec un niveau déterminé de ressources mémoire, de traitement et de stockage.
RedShift RA3 rapproche RedShift de l’expérience utilisateur de Snowflake en séparant parties traitement et stockage.
Snowflake offre une expérience quasi « serverless » : l’utilisateur configure la taille et le nombre des clusters de traitement. Chacun d’entre eux voit les mêmes données, et les clusters peuvent être créés et supprimés en quelques secondes. Snowflake propose plusieurs niveaux de tarification associés à des fonctionnalités différentes. Les calculs du benchmark sont basés sur le niveau Standard, le moins coûteux. Pour le niveau Enterprise ou Business Critical, le coût sera 1,5 ou 2 fois plus élevé.
Le forfait de BigQuery est similaire à celui de Snowflake, excepté qu’il n’intègre pas le concept de cluster de traitement, mais uniquement un nombre configurable de « slots de traitement ».
BigQuery on demand est un pur modèle serverless, dans lequel l’utilisateur soumet ses queries l’une après l’autre et paie par query. Le mode on-demand peut être beaucoup plus coûteux ou beaucoup moins coûteux, en fonction de la nature du flux de données. Un flux « régulier » utilisant la capacité de traitement en 24/7 sera beaucoup moins onéreux en mode forfait. Un flux avec une succession de pointes contenant d’importantes queries entrecoupées de longues périodes d’inactivité sera beaucoup moins coûteux en mode on-demand.





















